MFCC (Mel-Frequency Cepstral Coefficients)
기본개념
MFCC(Mel-Frequency Cepstral Coefficients)은 음성 신호의 특성을 분석하고 특징을 추출하는 데 가장 널리 사용되는 기법 중 하나입니다. MFCC는 인간 청각 시스템을 모방한 멜 스케일(Mel scale)을 기반으로 하여, 음성 신호의 주파수 분포를 효율적으로 표현합니다. 이러한 장점 덕분에 MFCC는 음성 인식, 화자 식별, 감정 인식, 음악 신호 처리 등 다양한 분야의 시스템에서 핵심 음향 특징으로 활용되고 있습니다
MFCC 개념 및 계산 방법
MFCC 특징 벡터는 일반적으로 다음과 같은 단계들을 거쳐 계산됩니다.
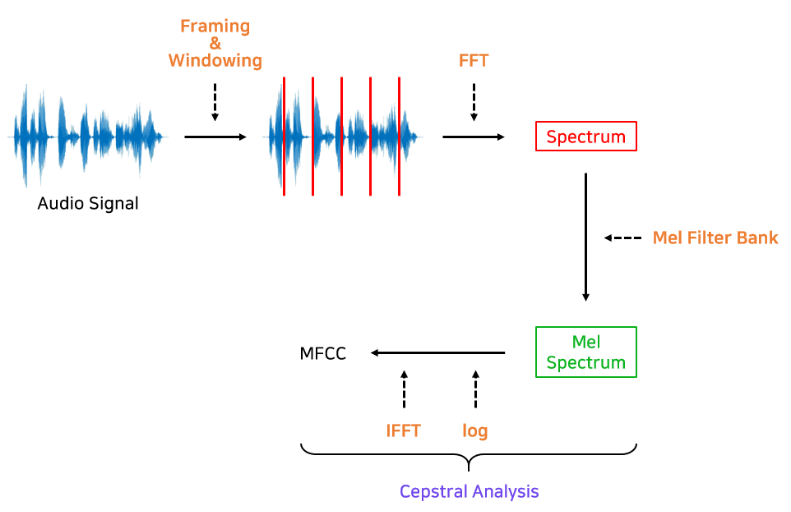
- 프레임 분할: 연속된 음성 신호를 짧은 프레임(예: 25ms) 단위로 분할합니다.
- 윈도잉(Windowing): 각 프레임에 해밍(Hamming) 윈도우를 적용하여 프레임 간 경계 부분의 불연속성을 완화합니다.
- 푸리에 변환(FFT): 윈도잉된 프레임에 대한 푸리에 변환을 수행하여 주파수 도메인 스펙트럼으로 변환합니다.
- 멜-필터뱅크 적용: 주파수 스펙트럼에 멜 필터뱅크(Mel-filter bank)를 통과시켜 인간의 청각 특성에 맞춰진 스펙트럼을 얻습니다. 멜 필터들은 삼각형 모양으로 겹쳐져 배치되며, 낮은 주파수 대역에서는 높은 해상도로, 높은 주파수 대역에서는 낮은 해상도로 에너지 값을 집계합니다.
- 로그 변환: 멜 필터뱅크를 거친 각 대역별 에너지 값을 로그 스케일로 변환합니다. 로그 스케일을 취함으로써 인간의 음량 지각과 유사하게 스케일링하고, 너무 큰 값의 영향을 줄입니다.
- DCT 변환(Discrete Cosine Transform): 로그 스펙트럼을 이산 코사인 변환(DCT)하여 켑스트럼 계수를 구합니다. 이때 고차 계수들은 노이즈에 민감하고 유의미한 정보가 적으므로 버리고, 낮은 차수의 MFCC 계수들만 특징으로 사용합니다. (일반적으로 프레임당 12~13개의 MFCC 계수를 추출하여 활용)
이러한 일련의 과정을 통해 시간-주파수 영역의 정보를 압축한 MFCC 특징들이 얻어지며, 음성의 스펙트럼 포락(spectral envelope)을 효과적으로 표현하게 됩니다.
Python을 이용한 MFCC 추출 예제
Python에서는 librosa와 같은 오디오 처리 라이브러리를 사용하여 손쉽게 음성 신호의 MFCC를 계산하고 시각화할 수 있습니다. 아래는 librosa를 이용한 MFCC 추출 예제 코드입니다:
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# 오디오 파일 로드 (예: sample.wav, 표본화 주파수 22050Hz)
audio_path = 'sample.wav'
signal, sr = librosa.load(audio_path, sr=22050)
# MFCC 계산 (프레임별 13개의 MFCC 계수 추출)
mfccs = librosa.feature.mfcc(y=signal, sr=sr, n_mfcc=13)
# MFCC 시각화
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis='time')
plt.colorbar()
plt.title('MFCC Visualization')
plt.xlabel('Time')
plt.ylabel('MFCC Coefficients')
plt.show()예시 – 오디오 신호에 대한 MFCC 계수의 시간별 변화 시각화 결과. 가로축은 시간, 세로축은 MFCC 계수 인덱스를 나타내며, 색상의 농도는 각 계수 값의 크기를 표현합니다. 이러한 스펙트럼 특성 시각화를 통해 시간에 따른 음색 변화를 한눈에 파악할 수 있습니다.
MFCC의 응용 분야
- 음성 인식 (Speech Recognition)
음성 명령이나 발화를 텍스트로 변환하는 AI 기반 음성 인식 시스템에서 MFCC가 핵심 음향 피처(feature)로 널리 사용됩니다 (예: Siri, Google Assistant 등) - 화자 식별 (Speaker Identification)
발화자의 목소리 특징을 분석하여 누구의 음성인지를 구별하는 데 활용됩니다. 개인마다 다른 성대 구조와 발성 특징이 MFCC 계수에 반영되므로, 이를 통해 화자의 신원을 인증할 수 있습니다. - 음악 정보 분석 (Music Genre Classification)
음악 신호의 음색(timbre)과 스펙트럼 특징을 나타내는 MFCC를 활용하여 음악 장르를 분류하거나 오디오 간 유사도를 측정하는 등 음악 정보 검색 분야에 사용됩니다. - 감정 인식 (Emotion Recognition)
음성의 억양, 높낮이 등의 특징을 MFCC와 함께 분석하여 말하는 이의 감정을 인식하는 데 활용됩니다. 예를 들어 콜센터 분석이나 감정형 챗봇에서, 음성의 MFCC 특징들을 기계학습 모델에 입력하여 화자의 감정 상태를 분류합니다.
결론
결론적으로 MFCC는 음성 및 오디오 신호 처리에서 매우 중요한 특징 추출 방법이며, 지난 수십 년간 다양한 음향 처리 시스템의 성능을 향상시키는 데 기여해왔습니다. 오늘날에도 음성 인식, 화자 식별, 음악 분석, 감정 인식 등 AI 음성 처리 분야에서 표준적인 특성으로 활용되고 있습니다. 특히 Python의 librosa 라이브러리를 이용하면 MFCC를 손쉽게 계산하고 시각화할 수 있으므로, 향후 음성 데이터 기반 프로젝트에서도 MFCC를 적극 활용하여 효율적인 신호 분석을 수행할 수 있을 것입니다.